I’ve been yearning to explore GraphQL for some time now and a daytime sleeper bus journey turns out to be the best excuse. I shall take a quick dive into it’s feature highlights also share some samples on how it can solve some real challenges for us. For brevity I’ve taken an example of our Task/Pending Task queing system (TaskTypes, Tasks, PendingTasks).
Let’s get started with GraphQL feature highlights:
1. Query Language for you API
This is the best way to understand GraphQL. Like we use SQL to explore our database, clients (end user applications) can use GraphQL to query data from you API. The similarity doesn’t end there - like in SQL it supports DDL (GraphQL schema), DML (GraphQL Mutation) and DQL (GraphQL Query).
Here is an example - GraphQL Query for a particular Task ID:
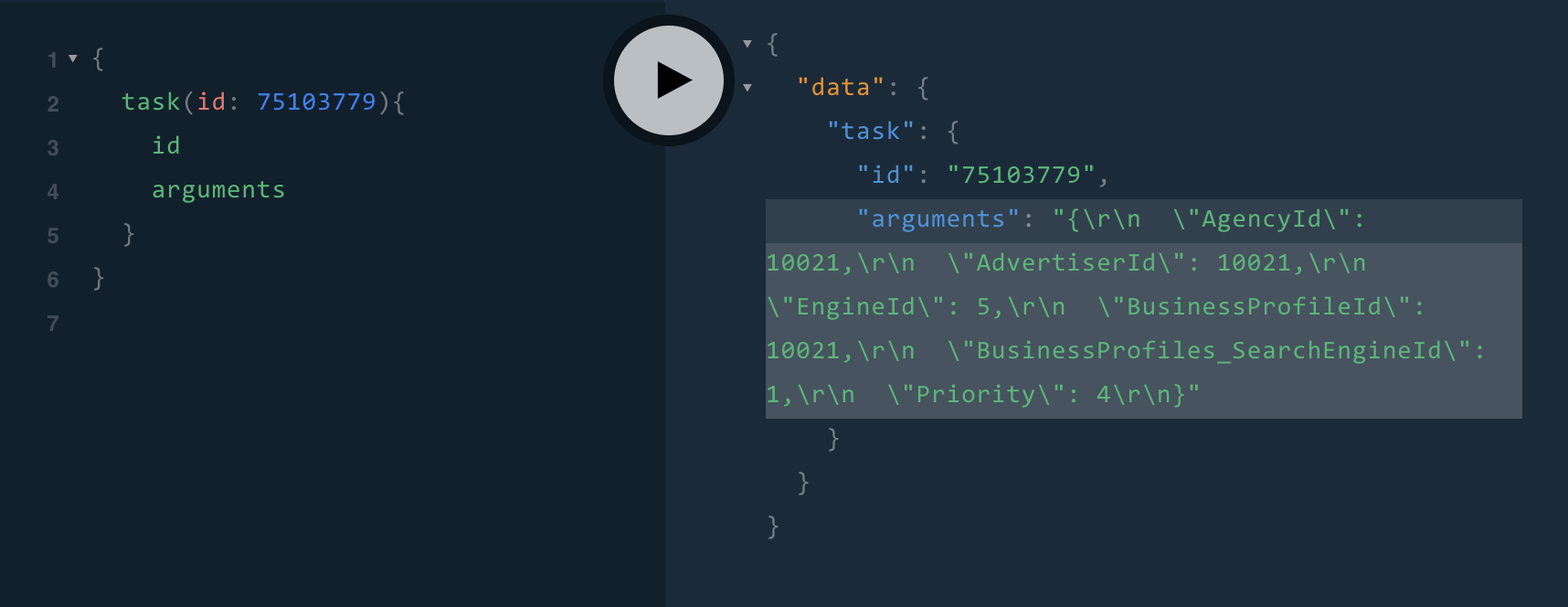
2. Query what you need
In case of REST - you don’t know what fields will get returned untill you make a request and see the response. One can always read the API docs - or use a client library but there is no discoverability or safety when it comes to REST as the response returns everything.
Example:
Let’s say you have a web app and mobile app which is displaying Task details (Id, TaskTypeId, Arguments, Priority). What if the mobile app doesn’t need to display the Task ‘Argument’ field? In case of REST considering both are using the same API endpoints - both will receive the ‘Arguments’ field for an API call for GET /tasks/75103779.
In case of GraphQL, the clients (web and mobile) can query for what they need.
Example Web Client - requesting for Id, TaskTypeId, Arguments and Priority:
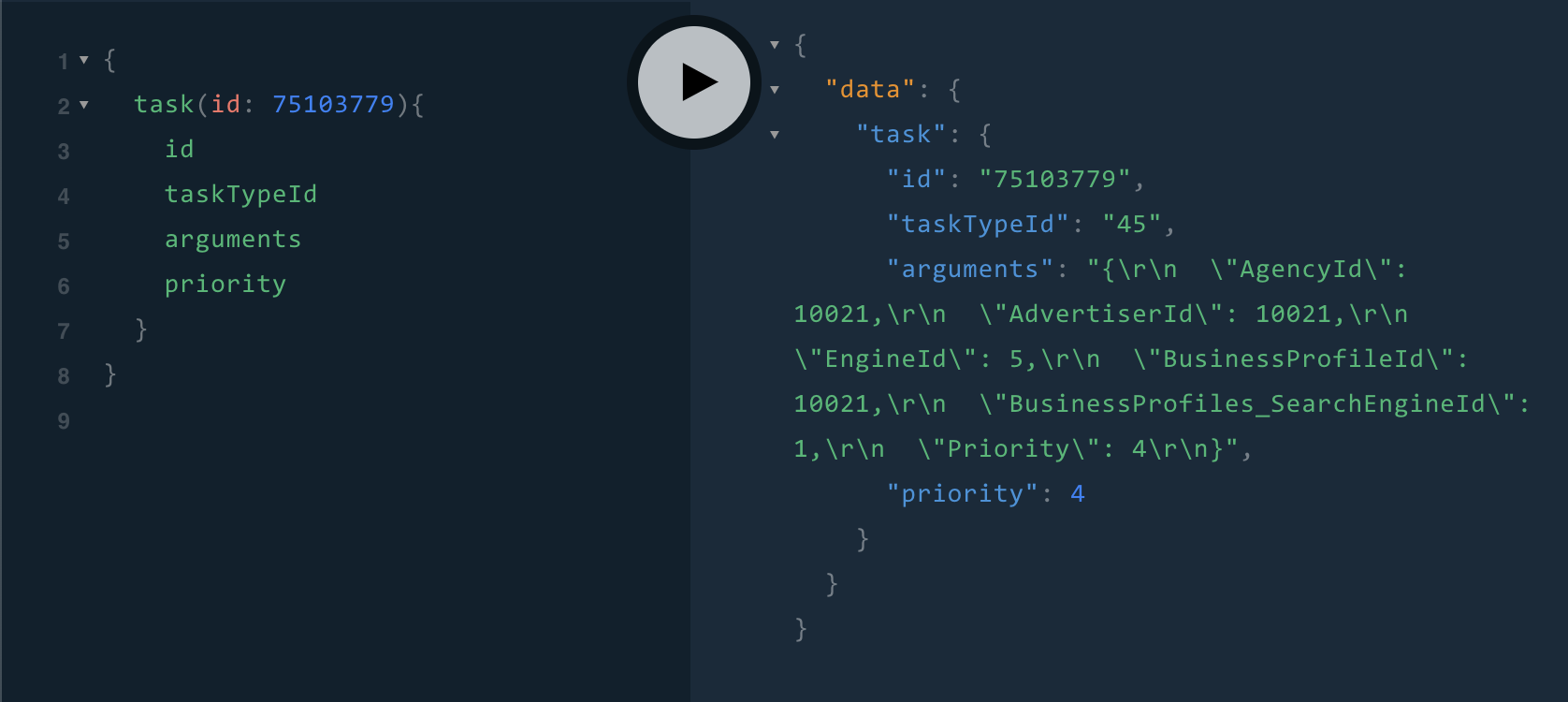
Example Mobile Client - requesting for Id, TaskTypeId and Priority:
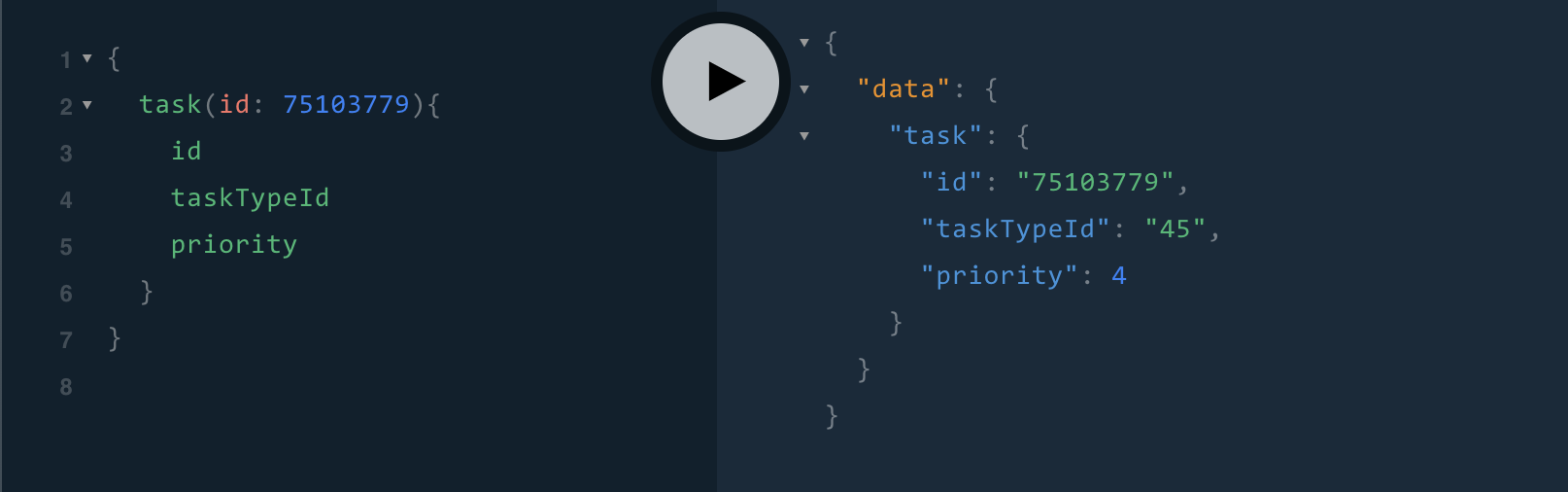
4. Nested resources
When using REST - you will always stumble upon edge-cases around whether REST resources should return responses containing multiple resorces.
Here is an example set of REST endpoints:
/tasktypes
/tasktypes/:id
/tasks
/tasks/:id
/tasks/:id/pendingstasks
/pendingtasks
/pendingtasks/:id
Use-case: If you want to display a Pending Task (id, taskstatusid) with it’s Task details (id, arguments).
Example with REST:
GET /pendingtasks/4480674
This will give us the id; and the taskid
GET /tasks/:taskid
This will give us the task details for the pending task
Example with GraphQL:
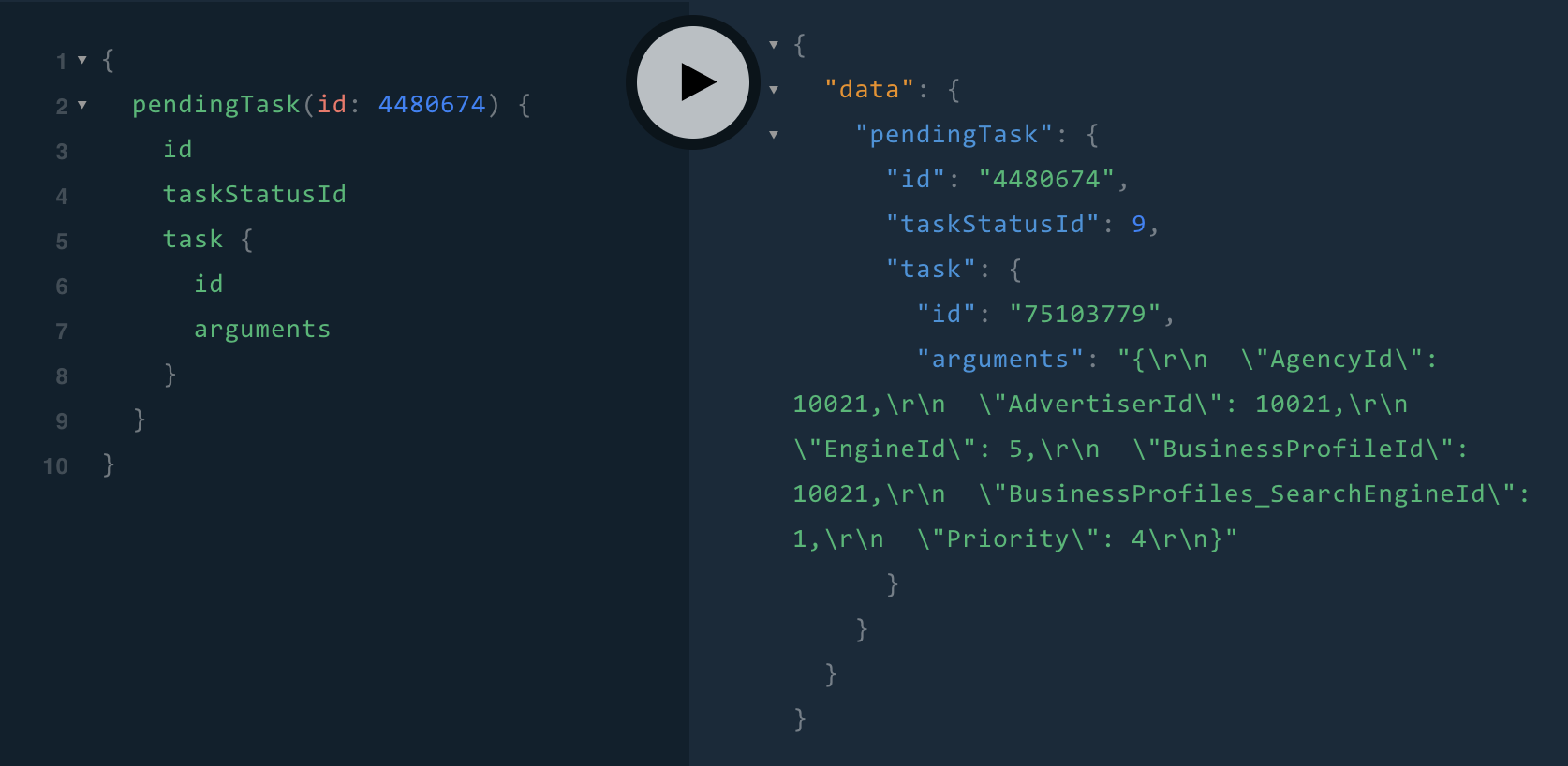
While we are at this - there is no restriction on what is returned as long as the client is expecting it.
Example GraphQL where you want Status of Pending Task 4480674 and details for TaskType 10
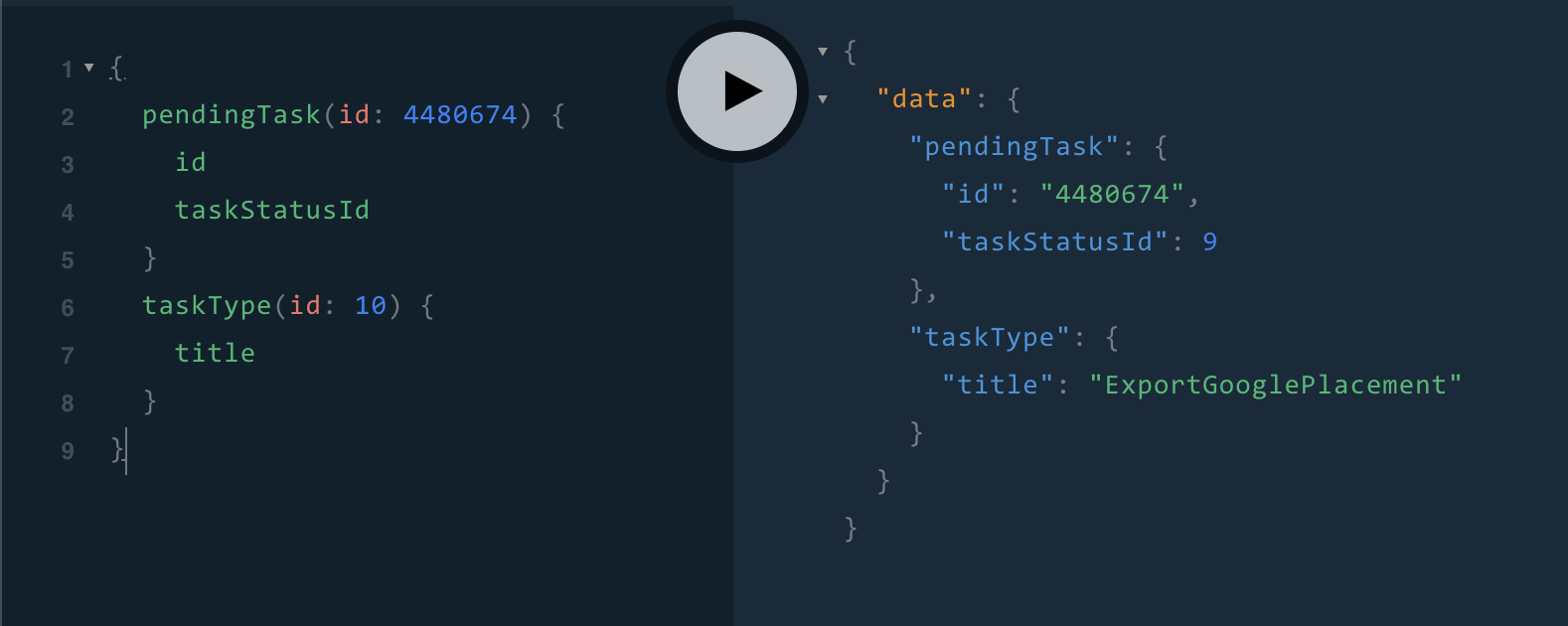
4. Version-less
As a side-effect of (2) and (3) - if there are not breaking migrations you don’t need a versioning for your API. You can keep evolving your schema and ageing fields can be deprecated slowly and hidden from new client integrations you can continuously evolve your API.
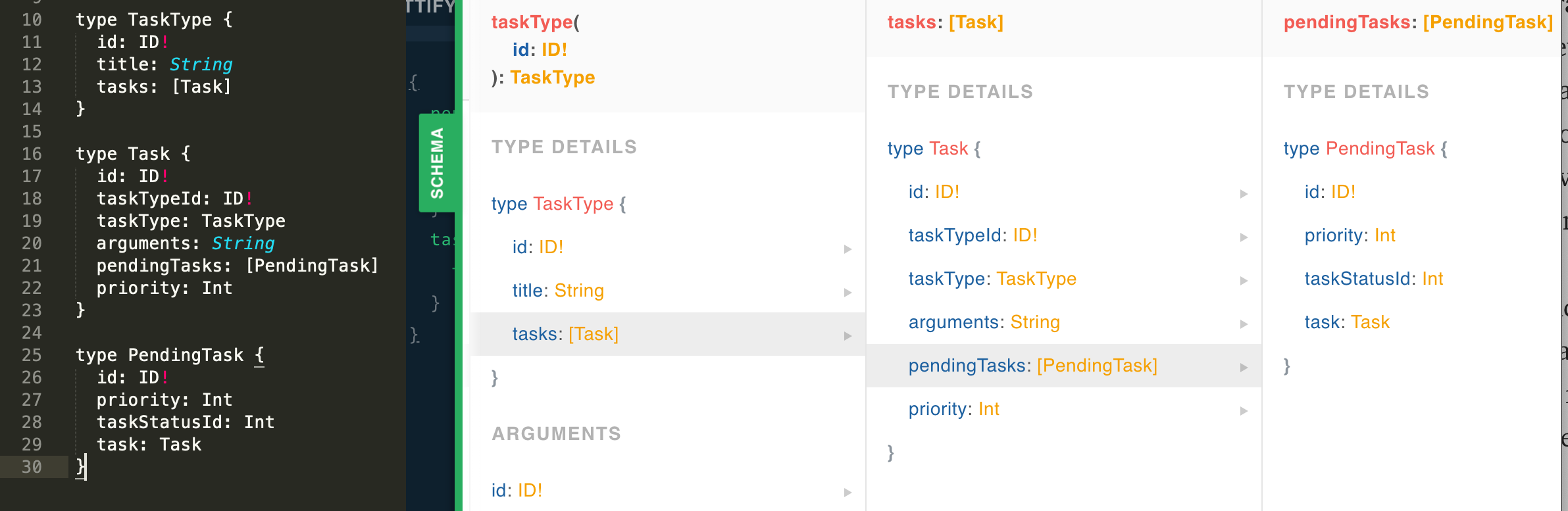
5. Strong Type System
GraphQL schemas are expressed as fields and types. This ensures the schema is self-documenting and better type checks during runtime.
6. Single endpoint
GraphQL acts as a single endpoint for all your queries. This is very different than the REST conventions we are used to where every resourse is a separate endpoint.
Let’s say your GraphQL server is running at http://localhost:4000 - you can directly send it a query using cURL or fetch to query data across all the mapped schemas.
Examples:
curl -X POST -H "Content-Type: application/json" -d '{"query": "{ task(id: 81061739) { id priority } }"}' http://localhost:4000/fetch('http://localhost:4000/', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Accept': 'application/json',
},
body: JSON.stringify({query: "{ task(id: 81061739) { id priority } }"})
})
.then(r => r.json())
.then(data => console.log('data returned:', data));7. Layering GraphQL over existing REST API
GraphQL specification defines a query language and the execution engine. In code it’s defined as a schema and a set of resolvers. The actual code for the resolvers isn’t part of the specification and hence there are endless possibilities as long as you can find a resolver for your backend. In more concrete terms, the above examples are possible using the sequelize which is an ORM for mssql and graphql-sequelize which is a resolver for graphql queries targeted at Sequelize models or associations. In the same way, you can have resolver which is fetching data from your existing REST API (or even multiple REST APIs).
GraphQL is not a silver bullet - it has it’s own gotchas. Here are some you would want to keep in mind:
1. Fat Clients
A direct consuqeuence of ‘query what you need’ - is that the clients are more context / scehma aware. Depending on the client libraries you use this could be a boon or a bane.
2. Rouge clients / Complex Query Optimization
In a case of REST, we consciously expose the data through the API. What this allows us to ensure is being able to optimize the queries the API is making on the database. In case of GraphQL we allow clients to make arbitary/adhoc queries - optimizing for such usescases can become complicated. In addition, N+1 problem is a classic problem which hits ORMs (yes - EF, I’m looking down upon you) and REST APIs alike. GraphQL is no exception and to avoid such cases one needs to use a dataloader. DataLoader is a generic utility to be used as part of your application’s data fetching layer to provide a consistent API over various backends and reduce requests to those backends via batching and caching.
Closing Thoughts
With us moving towards API-first, we are already facing some of the above challenges across teams with conventional REST API design. GraphQL looks like a strong contender for us to evaluate and experiement with. If you are excited about possibilities of GraphQL, please feel free to reach out to me with ideas.