The Big Data ecosystem has grown leaps and bounds in the last 5 years. It would be fair to say that in the last two years the noise and hype around it have matured as well. At DeltaX, we have been keenly following and experimenting with some of these technologies. Here is a blog post on how we built our real-time stream processing pipeline and all it’s moving parts.
- Big Data Processing Models
- History of Experimentation at DeltaX
- Building the Real-time Stream Processing Pipeline
- Looking Forward
Big Data Processing Models
Before I take a deep dive into how we went about building our data pipeline - here are some models I would like to describe:
Batch processing
We have been using batch-processing as a paradigm on the tracking side from the start. Overall, when Hadoop as an ecosystem came to the fore - ‘map-reduce’ as a powerful paradigm for batch processing on bounded datasets got wide adoption. Batch processing works with large data sets and is not expected to give results in real-time. Apache Spark works on top of Hadoop and primarily falls under the batch processing model.
Stream Processing
Stream processing as a paradigm is when you work with a small window of data, complete the computation in near-real-time, independently. asynchronously and continuously. Apache Spark Streaming (micro-batch), Apache Storm, Kafka Streams, Apache Flink are popular frameworks for stream processing.
History of Experimentation at DeltaX
Genesis
When we started architecting our tracker back in 2012, it was also the time when the Hadoop ecosystem was catching a lot of eyeballs. Being the curious mind and dabbling with it a little - it was thrilling to see the power of scalable distributed file system (Hadoop) and map-reduce as a paradigm. We were small and the data that we were expecting to see at that time in the near future wasn’t anywhere close to Big Data and so we never ventured towards it. But as a side-effect of the exploration, the files that we generated from tracker were JSON and were processed in batches.
Exploring Apache Storm
We built a POC in 2014 for our tracker and dabbled in stream (event) processing as a paradigm. This was an interesting exploration and conceptually our use case fit very well with the ‘spouts’ and ‘bolts’ semantics from Apache Storm. This was also our first time working with ZooKeeper and Kafka and I must admit it wasn’t a breeze to get them to work.
Exploring Amazon Kinesis
Around 2015 Joy worked on a POC for ingesting click data into Amazon Kinesis. Compared to Apache Kafka, working with a cloud-managed service felt refreshing. We explored this immediately on launch and it lacked a lot of bells and whistles which are now baked into the service. Read further to see how we shall close the loop on this.
Exploring Datastores
Data stores have always been of interest to us on the tracking and ad-serving side. Having dabbled with SQL, SQL Column stores, Redis, AWS DynamoDB, AWS S3 and MongoDB at varying times - we would always be interested in the next exciting store. It was then when we came across Druid. Druid is a distributed column-store database and it caught our fancy for it real-time ingestion and sub-second query times. Amrith also happened to a fairly detailed deep-dive on it and dabbled with it as part of #1ppm. I scanned the docs which explain their data model and various trade-offs in fair detail. Reading through Druid docs and understanding it’s internal working set a benchmark with regards to what we should expect from a sub-second query store.
Exploring Stream Processing and Apache Spark
It was Dec 2016 when we decided to go neck deep this time with Amrith leading from the front. The ecosystem had matured, we had learned from our previous explorations and the volume of data had substantially grown. We explored Apache Kafka and it’s newly introduced streaming model. Post POCs, follow-up discussions and deep-dive we were convinced that the computing framework, tooling, paradigm and unified stack that Spark provides was suited, mature and superior to other options available. This was also the time when Joy hopped on the bandwagon. There were some fundamental challenges we needed to overcome to confidently take this to production.
Here are some challenges we faced with Apache Spark:
- We were creating rolling hourly log files by advertiser; which was close to 15K per hour and this was only growing
- We were using AWS S3 supported EMRFS which is is an implementation of HDFS for S3, but it wasn’t really meant for working with thousands of small files, instead it was more suited for processing a small number of huge files.
- We deviated towards the batch processing paradigm by running the AWS EMR cluster every half an hour, yet we were not able to figure out a clean way to ingest the summarized data into individual advertiser BPs. This was more of a bottle next with regards to our multi-tenant isolation across advertisers
- AWS EMR cluster wasn’t very stable and something we were not very confident about. Also, the overall provisioning and dynamics of resources allocation were not something that was easy to factor in for production workload.
- We were able to process a day’s odd data in fractionally incremental time vs. half-hour data which was a complete bummer for us. On exploring further - the stack we were working towards was ideal to process large volumes of data over a week to two week period in one shot instead of trying to process half-hour worth of data.
Lastly, I must confess none of these should be looked at as shortcomings for Apache Spark but more as architectural trade-offs given what was possible at that point in time given what was in place, bandwidth, and resources. Given the right use case, I would hands-down go back to booting up an AWS EMR cluster to process a few months worth of data using Apache Spark.
P.S: Amrith has a fairly detailed set of notes about how we went about this exercise as a draft post with title ‘Igniting Spark’ and can be read by anyone internally.
Building the Real-time Stream Processing Pipeline
By this time we had a series of learnings and some clear goals in mind:
- Stream processing as a paradigm suits our use case the best
- Easy to maintain or managed service in the cloud would be ideal
- Developer friendly and peace of mind was of utmost importance
- Being able to ingest streaming data and query summaries was important
- Good to have a way to run batch processing framework for machine learning, data crunching, and analysis
Architecture Components
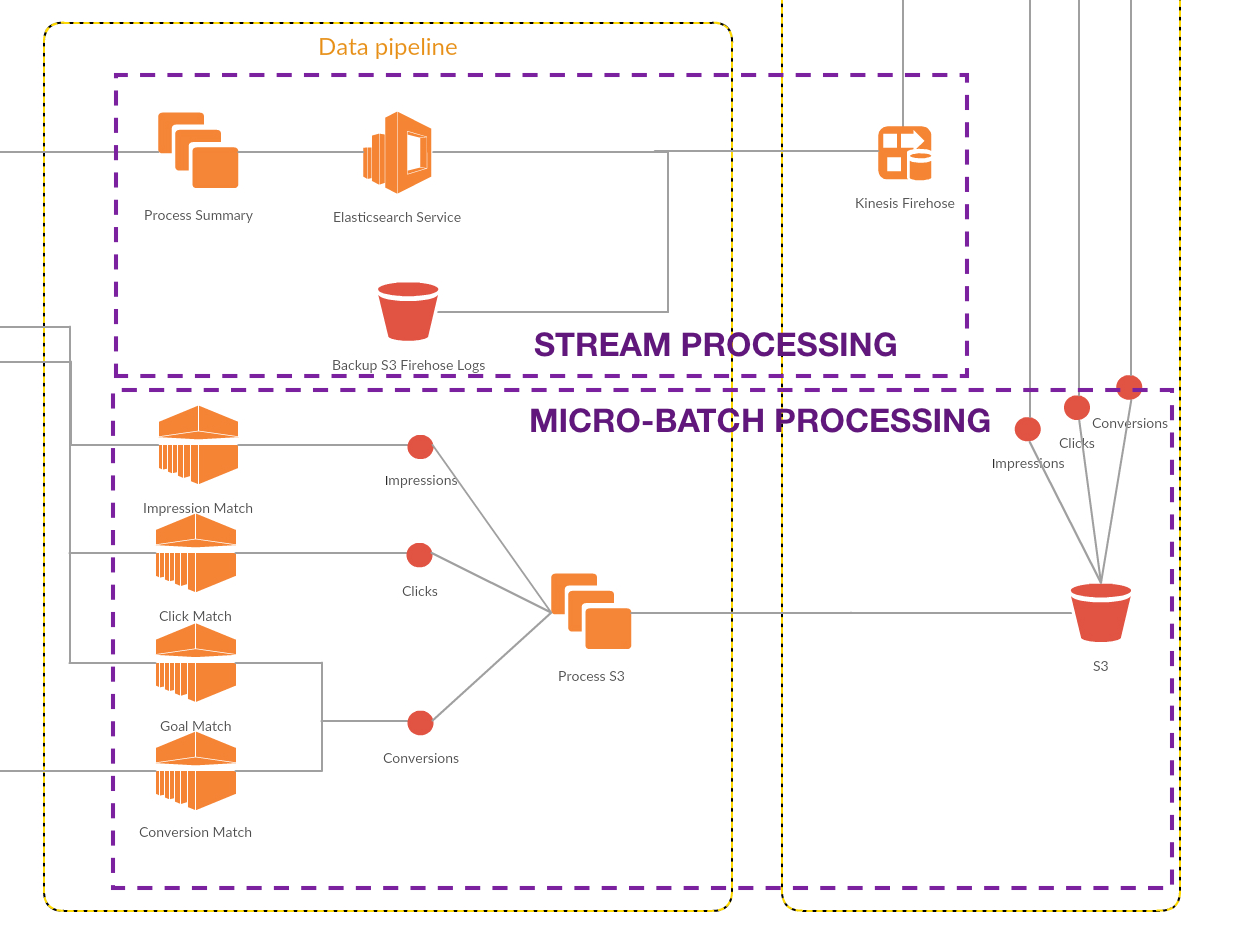
Click here to view full architecture flow
Event Producers
Our core tracking and ad serving stack are built from scratch on Node.js. It’s on AWS and auto-scaled. The async event-driven approach of Node.js works perfectly right for producing async events. We integrated the Kinesis Firehose SDK and push events to Kinesis Firehose
Streaming Queue
Kinesis Firehose is a fully managed streaming queue with configurable destinations. It also supports running custom lambda functions on every event. Event processing and the scalable serverless model of processing together is extremely powerful. We have configured two destinations for our Kinesis Firehose application - Amazon S3 for batch processing logs and Amazon Elasticsearch for near-realtime summarization queries.
Amazon Elasticsearch
Using Elasticsearch as part of our stack is a story in itself. We had looked into Elasticsearch primarily for log monitoring the first time. Elasticsearch as an ecosystem has evolved from its primary search driven use-case to a wide array of time-series and aggregation use-case. Like any NoSQL databases, you want to follow the access-oriented pattern and model it right. With Elasticsearch in our arsenal, we were also able to build a pull-based architecture - where workers across advertisers pull the required data from Elasticsearch. With Kinesis Firehose + Elasticsearch we have been able to keep the data freshness to around 15 minutes from a click to its summary being available. Jaydeepp has planned to write a multi-part series on Elasticseach - Part 1 is already published.
Streaming Analytics
Kinesis Analytics allows running streaming SQL window functions on events in Kinesis Firehose. This could be useful to run any kind of real-time anomaly detection, fraudulent click protection or rate limiting.
Batch Processing and Analytic Workloads
The AWS S3 logs deposited by Kinesis Firehose can be used for batch processing and analytic workloads. We use AWS Athena a managed PrestoDB service to do all the heavy lifting when it comes to analytic workloads across advertisers and big date ranges. You can do this while still writing vanilla SQL. Anything more complicated and you can start an AWS EMR cluster and run an Apache Spark job to do the data crunching for you.
Looking Forward
Just last week, Vamsi blew me away with his take on modelling the tracking data to a Graph Database.
Here is what I have learned from this experience and something you would have already felt after reading about this journey. This is not where it ends. You are never able to connect the dots looking forward. Considering we are working with unbounded data sets - all we can do is to keep streaming and keep processing!