At DeltaX, we have multiple use-cases of Redis.
- As a Session Store
- As an intermediate entity lookup cache store
- As a key store to identify most used business profiles
This article talks gives a little background on how we latched onto Redis, some gotchas, and some free advice :)
Quoting the website,
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs and geospatial indexes with radius queries. Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
Background
A couple of years ago, we took the horizontal scaling approach for our web app. Being a .net MVC app, we took advantage (read as misuse) of ASP.NET’s Session.
And that was what held us by the neck when we needed to scale out! Session was an in-memory, per instance (of the app) object.
That’s when we stumbled onto the Session State Provider. This allowed us to offload our Session into a Redis instance (without any code changes!).
So, we started off using a standalone self-run version of Redis on our bare-metal servers.
Today’s Usage
Well, we’ve moved on from bare-metal to a cloud-first company. So naturally, we picked Azure Redis.
No fuss setup and monitoring right out-of-the-box. Our App Service (on Azure of course), was happy interacting and using Azure Redis as it’s Session Store.
Having a full managed Redis meant we had stats right in fron of us.
- Hits and Misses, Gets and Sets, Connected Clients
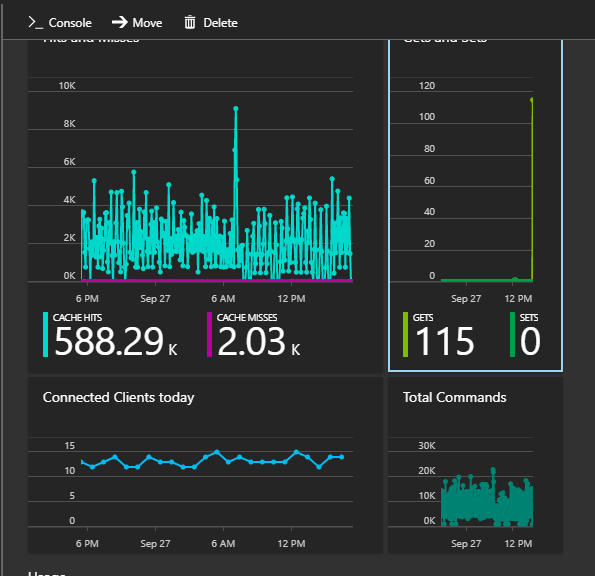
We are still happy (please do read the gotchas section below) with using Redis as our Session Store.
Redis as an entity cache
Our tracking system maps web data (clicks, impressions) to the campaigns that advertisers are running.
Our primary DB is Azure SQL Database. The processing workers were constantly querying the entity tables (Campaigns, Adgroups, Ads) to map (JOIN) the log level data to the ads.
This caused high usage (DTU) of our DBs. But the funny bit is that this data was not continuosly changing - it was pretty static. Voila, the perfect use case for caching the results of the queries.
Here comes Redis again! We built an intermediate cache layer for our workers.
Process log -> Parse JSON -> Get Entity Data from Cache -> Dump to database.
The Redis magic is in Step 3 - “Get Entity Data from Cache”.
It goes like :
Worker: Hey Cache, give me the data for this Ad ID 123.
Cache: (internal murmuring) Oops, I don't have it. Let me go get it from the Database.
SELECT C.Name, AG.Name, A.Name
FROM Campaigns C
JOIN Adgroups A
JOIN Ads A
WHERE A.Id = 123
Cache: (still internal murmuring) Now that the DB has given me this data, let me keep it in my pocket for some time.
Cache: Hey Worker, here is the data.
Another few minutes later,
Worker: Hey Cache, give me the data for Ad ID 123 again.
Cache: (oh yeah!) Here, take it!
As this dialogue makes it clear, this shared cache is pretty useful to us. Especially because we process clicks and impressions in parallel. But they are typically looking for the same set of Ads.
Redis to hold a usage counter
We use Redis to hold usage stats. Everytime someone visits the home page, we log this usage data into Redis.
Later, we sort this in a descending fashion and call these our frequently used business profiles.
We run a warm-up script for these profiles.
Here’s the description of the usage :
User visits home page of Profile 1 -> Increment number of visits for Profile 1
We use Redis’ INCR to track a global counter.
At a later point in time, we get these visit info from Redis and run a warm-up script for the top visited profiles.
Gotchas
Everything has it’s kinks. So does our usage of Redis.
Timeout issues
Timeout performing EVAL, inst: 1, mgr: Inactive, err: never, queue: 4, qu: 0, qs: 4, qc: 0, wr: 0, wq: 0, in: 10129, ar: 0, clientName: RD000D3A31D896, IOCP: (Busy=0,Free=1000,Min=4,Max=1000), WORKER: (Busy=8,Free=32759,Min=4,Max=32767), Local-CPU: unavailableust
We faced this sort of timeout issues on an ongoing basis. That was until we had Azure Support look into the issue.
This usually occurs due to sudden burst in the request/response being processed by the application. You should consider configuring your threadpool setting to handle such scenarios. The bottom line is the no. of Minimum threads in the threadpool should always be more than the busy threads. In another word, there should always be some threads already available in the threadpool to serve the requests. Please have a look at the article below for more details: https://github.com/StackExchange/StackExchange.Redis/blob/master/docs/Timeouts.md#are-you-seeing-high-number-of-busyio-or-busyworker-threads-in-the-timeout-exception
We have managed to fix this with the following approach :
protected void Application_Start()
{
// Configure IOCP and Worker threads to avoid potential Redis timmeouts
// https://gist.github.com/JonCole/e65411214030f0d823cb#recommendation
// https://msdn.microsoft.com/en-us/library/system.threading.threadpool.setminthreads(v=vs.100).aspx#Anchor_2
// ReSharper disable once InconsistentNaming
int currentMinWorker, currentMinIOC;
// Get the current settings.
ThreadPool.GetMinThreads(out currentMinWorker, out currentMinIOC);
Log.DebugFormat("Application_Start : Current configuration value for IOCP = {0} and WORKER = {1}",
currentMinIOC, currentMinWorker);
int workerThreads = string.IsNullOrEmpty(ConfigurationManager.AppSettings["WORKER_THREADS"])
? currentMinWorker
: Convert.ToInt32(ConfigurationManager.AppSettings["WORKER_THREADS"]);
int iocpThreads = string.IsNullOrEmpty(ConfigurationManager.AppSettings["IOCP_THREADS"])
? currentMinWorker
: Convert.ToInt32(ConfigurationManager.AppSettings["IOCP_THREADS"]);
// Change the minimum number of worker threads and minimum asynchronous I/O completion threads.
if (ThreadPool.SetMinThreads(workerThreads, iocpThreads))
{
// The minimum number of threads was set uccessfully.
Log.DebugFormat(
"Application_Start : Minimum configuration value set - IOCP = {0} and WORKER threads = {1}",
iocpThreads, workerThreads);
}
else
{
// The minimum number of threads was not changed.
Log.Debug("Application_Start : The minimum number of threads was not changed");
}
...
}
Max connections
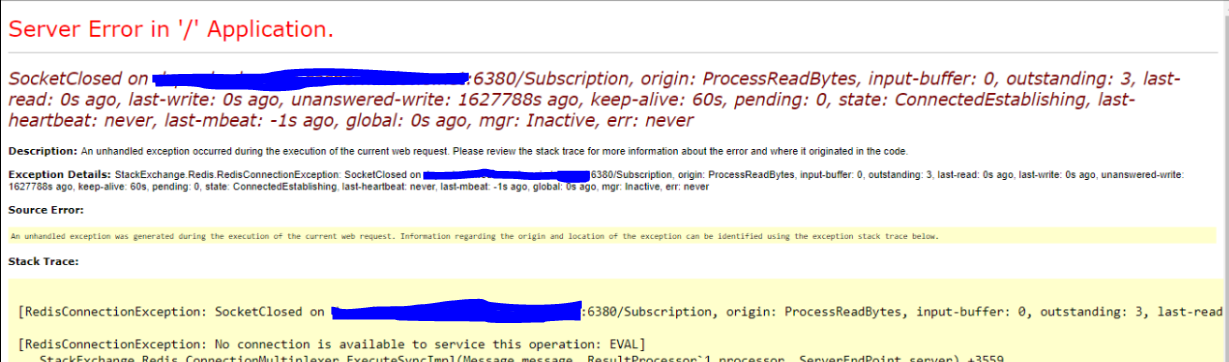
You have been warned! If you do not follow recommended practices for connecting to Redis, you are likely to face connection troubles.
The recommended pattern suggests to use ConnectionMultiplexer and re-use the same object for subsequent connections.
In our case, turns out that using ConnectionMultiplexer in an Azure Function was a bad idea. Everytime the function was invoked, a new connection was made to the redis server. And since the functions don’t die after completion (Always ON functions), the connections are not disposed either!
As in most cases where a leak occurs, a simple using block sufficed.
public static class TimerTrigger
{
[FunctionName("TimerTrigger")]
public static void Run([TimerTrigger("*/5 * * * * *")]TimerInfo myTimer, TraceWriter log)
{
string redisConnectionString = ConfigurationManager.ConnectionStrings["RedisConnectionString"].ConnectionString;
string redisServer = ConfigurationManager.AppSettings["RedisServer"];
using(var redisConnection = ConnectionMultiplexer.Connect(redisConnectionString))
{
var redisServer = redisConnection.GetServer(redisServer, 6379);
var keys = redisServer.Keys(pattern: "AY-*");
foreach (var key in keys)
{
log.Info(key);
}
}
log.Info($"C# Timer trigger function executed at: {DateTime.Now}");
}
}
https://stackoverflow.com/a/38485996 So be cautious when using StackExchange.Redis in an Azure Function!
We faced an issue a little while ago (a week or two ago). The issue was that the web app was unusable - turns out, this Azure function ate up all available connections and our web app (which is using Redis for Session Storage), couldn’t connect to the Redis instance. Bummer!
Experimental
There are also some interesting experiments with Redis.
- https://github.com/danni-m/redis-timeseries - Possibility of using Redis as a time-series database.
Being a super fast, in-memory store (and support for persistence) means that Redis has a wide array of uses.