At DeltaX, we have been dabbling with Internet Scale and High Availability for our core tracking and ad-serving services. We have had our fair share of battles, wounds, victories and a host of untold stories. Today, I shall dabble into some learnings keeping the stories for another day.
When designing architecture for mission critical systems the two most commonly discussed aspects are scalability and availability. Most often than not both aspects are used interchangeably. Scalability is about being able to handle increasing load while availability is keeping the system operational by decreasing downtime. Designing Highly Available systems is focusing on the qualitative measures to reduce downtime and eliminating the single point of failures (SPOFs). Here are some learning and thoughts on things to consider while architecting an HA system.
1. Accept Failure
This is contrarian to what we set out to achieve but with all things that start in the head, you have to first get the monkey out of your head. So, if someone comes up to you and informs you that have to build a system which has zero downtime and should be running 99.999% uptime (also called five 9s which is a gold standard). Our first reaction would be to ensure we code in such a way that the system will never fail, handle all exceptions, scale to ensure that it can handle increasing load and hence will never have a downtime. Instead for a second, pause and first accept failure. Accepting failure doesn’t mean that you are building for failure but you accept that irrespective of what you do - it can still fail and so you have to consider, reconsider and plan your system around being able to fail and still keep running.
Next two learnings will talk more about how to fail - like a gentleman.
2. Redundancy, Failover and Recovery (avoid SPOF)
Building redundancy is about ensuring that there are alternate paths in the system to keep functioning (albeit at lower capacity) while failover is switching to the alternate path. The switch over ideally has to be automatic to ensure that there is no manual intervention needed. Once we have a system which fails over it’s very important to have a recovery plan to be able to resurrect the failed path otherwise there is a high chance the will result in additional load and may cause congestion or subsequent failures (snowball-effect). The recovery may be automatic or even manual.
Let’s take a classic example of a web server to understand redundancy and failover.

Now let’s add a load balancer in between and have two servers responding to requests; while the load balancer will ensure that whichever server is ‘healthy’ will be the one receiving requests from the load balancer. As soon as it detects that one of them is ‘unhealthy’ it shall redirect the requests to another one.
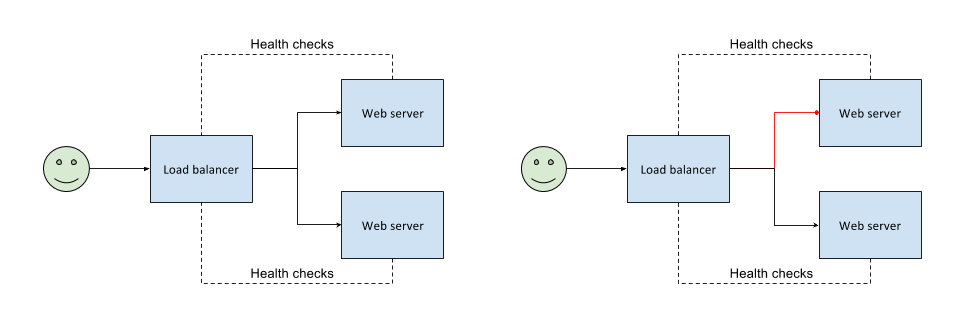
Although, this ensures that we have redundancy and also automatic failover - the load balancer in itself is now a SPOF. So, let’s try an alternate setup where we have two load balancers and two servers.
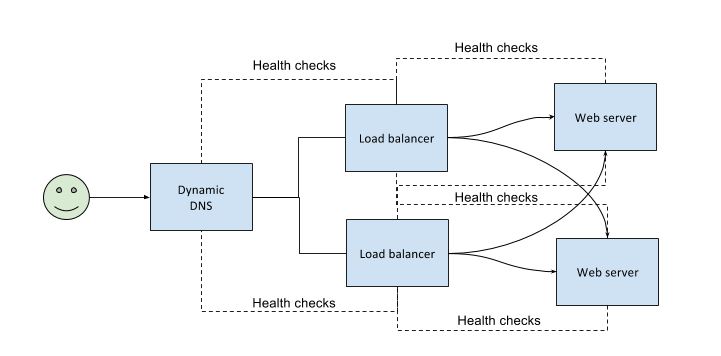
This is a simplistic schematic setup; production systems are more complex and have more moving parts. While we ensure automatic failovers it’s really important to be able to recover from failure. A simple example here could be that once the load balancer detects a web server to be ‘unhealthy’ it’s important to ensure that either we are able to automatically recover by swapping out the web server with a healthy one.
3. Performance Monitoring & Alerts
You can’t improve what you can’t measure. Also, for any HA system monitoring and alerts can’t be an afterthought. Monitoring is ensuring you are measuring health and performance indicators while alerts are ensuring you get timely and actionable information about the system.
Bonus Tip: To see if your system can handle failure, failover, recover and you are able to receive alerts while chaos hits the roof - you can simply log into any of your servers and simply power-off! Think this is a joke? Netflix actually built a tool called Chaos Money to do exactly this. Chaos Monkey is a service which identifies groups of systems and randomly terminates one of the systems in the group.
Architecture for DeltaX HA services
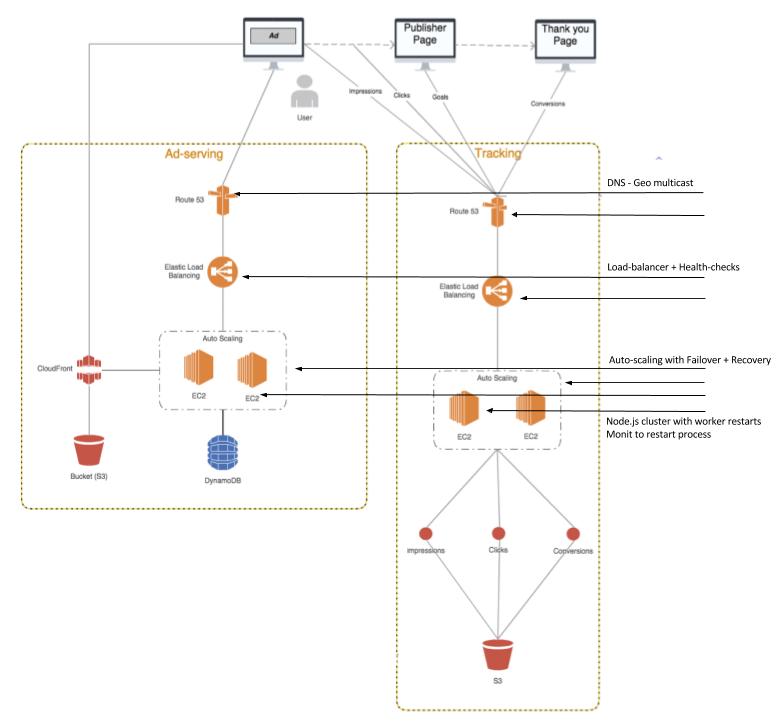
We leverage the AWS Cloud to the fullest - right from Route53, ELB, EC2 auto-scaling and S3 for the persistent store. I must note here that adopting the cloud doesn’t really mean that you are set for HA but it definitely makes your job easier with a suite of services and health monitoring system.
For redundancy, we use multiple EC2 instances under an Elastic Load Balancer(ELB) for redundancy. In each of the instances, we have multiple workers running using the Node.js cluster module. Failover and recovery are handled at multiple levels. At the worker level, we have the cluster module which instantiates a worker if one dies; monit monitoring the server process within each instance with a trigger for restart if needed. ELB health checks to route traffic between multiple instances; also to ensure auto-scaling requirements are met. Monitoring & alerts are handled through Amazon Cloudwatch and Amazon SNS.
Overall, we still have some areas in the architecture to improvise upon and further eliminate SPOFs. Like any serious HA architecture - you can’t take anything for granted; if you do the Chaos Monkey may strike.