Getting the basics
If you believe in ‘Manners maketh Man’; then you would agree when I say ‘Indexes maketh the Query in SQL’. In this post, I plan discuss the most basic types of indexes available - clustered and nonclustered. I also plan to show with examples on how they work, individually and together and compare each case to the real world.
Sugar, spice and everything nice
Lets consider a table which stores information of a Phone Book. It would be safe to assume the following columns - first name, last name and number.
USE [Playground]
GO
CREATE TABLE [dbo].[Phonebook](
[FirstName] [varchar](50) NULL,
[LastName] [varchar](50) NULL,
[Number] [varchar](50) NULL
) ON [PRIMARY]Insert some dummy data into the table, or you can head over to Mockaroo to download the insert script.
We shall now execute some queries and get an understanding of what’s happening by examining the execution plan.
Find all the numbers with first name ‘Michael’
Select * from Phonebook where firstname = 'Michael'
Taking a look at the execution plan, we can see that a full table scan is required to get the result. A seek means only a set of rows are read from the table and not all rows. A scan means all the rows of the table are read.
For a moment - let’s think about an actual phone book. We would have to go through the whole book, to make sure we have ALL the numbers with last name ‘Michael’. There is no way of making sure we have ALL the required numbers without going through the whole book. Imagine going through each and every name in the phonebook to find out a few names!
A book without an index is useless, unless its a small one with few pages. An index helps us find what we are looking for quickly, if used in the right way. Just like the index of a phone book, the table index is a data structure that holds information regarding the table’s data.
Nonclustered Indexes
Definition: “Nonclustered indexes have a structure separate from the data rows. A nonclustered index contains the nonclustered index key values and each key value entry has a pointer to the data row that contains the key value.”
Lets start by creating a nonclustered index on the table, on the columns last name and first name.
create nonclustered index IX_LastName_FirstName on Phonebook (LastName,FirstName)This will create the index, with lastname and firstname columns as key columns.
In the real world scenario, imagine having a separate handbook as an index. This index book will have information about the numbers in the actual phone book.
Get all entries with last name ‘Reynolds’ and first name ‘Willie’
select * from Phonebook where lastName = 'Reynolds' and firstname = 'Willie'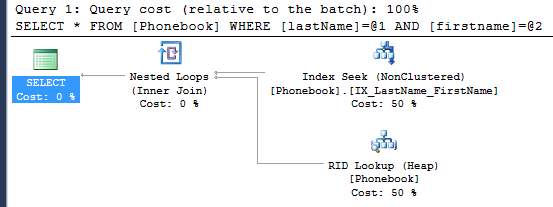
The execution plan shows that there is an index seek, with an RID lookup.
Since we have created an index which includes lastname and firstname as the key, the sql query optimizer can find values for firstname and lastname columns in the index itself. RID lookup : Our current index includes values for lastname and firstname only. Since we are selecting all the columns in the query, the values for number column aren’t present in the index. This is where the pointers to the data rows of the table come into play. If the query optimizer cannot find all the data required by the query, it makes a visit(lookup) to the actual table.
Lookups can be ignored for small tables, but they can degrade the query performance for very large tables. How do we avoid this lookup?
- Add the number column as an included column to the nonclustered index. What this means is the values for the number column will also be present as a part of the index.
- Modify the query to fetch only those columns which are present in the index.
if we just fetch the names select lastname,firstname from Phonebook where lastName = ‘Reynolds’ and firstname = ‘Willie’
We can see that an index seek is sufficient! This is because we are looking for the last name and first name only, which are already present in the index, so a lookup on the table is not required.
If an index includes all the information required by a query, its called a covering index.
Clustered Indexes
Definition: “Clustered indexes sort and store the data rows in the table or view based on their key values. These are the columns included in the index definition. There can be only one clustered index per table, because the data rows themselves can be sorted in only one order.”
A clustered index affects how the table rows are stored and is something that is “tightly bound” to the underlying table. Unlike the nonclustered index, which is a separate structure.
Lets drop the earlier nonclustered index, and add a clustered index on lastname and firstname in ascending order. This will sort the table data by last name and then first name.
create clustered index IX_LastName_FirstName on Phonebook (LastName,FirstName)Get all the entries
select * from Phonebook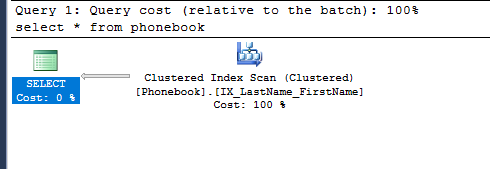
Requires a full table scan Since we have a clustered table (table with clustered index) now, the scan happens through the clustered index.
Get all entries with last name ‘Bishop’
select * from Phonebook where lastname = 'Bishop'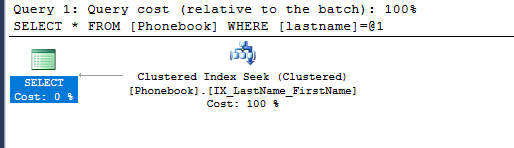
An index seek is enough to get our result as we have created an index including lastname and firstname
Get an entry with a particular number
select * from Phonebook where number = '86-(921)813-3429'
The phone number is not a part of the clustered index, hence a full scan of the index is required because the numbers are not sorted!
How to avoid the above scan?
Add the number column as an included column to the clustered index? No. As I mentioned before, the clustered index affects how the rows itself are stored and ordered. What this means is, the clustered index is actually the index structure plus all the table rows. So all the data is “included” already!
This also means that if a table has a clustered index, every query, WILL use the clustered index. Explicitly or implicitly.
So, to avoid the scan, we can
- Modify our query to utilize existing indexes.
- Add a nonclustered index with key as number.
Lets try the second one.
create nonclustered index IX_Number on phonebook (number)Now, lets retry our earlier query to find a number
select * from Phonebook where number = '86-(921)813-3429'
Now that we have an index for number, the query optimizer will use the nonclustered index to get the number and internally use the clustered index to get the last name and the first name!
A table can have a clustered index, and multiple non clustered ones. So there’s a high possibility two or more indexes are created with similar columns Eg. Consider our phonebook table. Clustered index - LastName,FirstName If we had a non clustered index - LastName,Number. LastName column would be included in both the indexes and hence is “overlapping” with the clustered index.
What did we learn
- Avoid RID lookups in the absence of clustered indexes since it’s an additional operation, and may end up being costly in case of large tables.
- Queries on clustered tables, will always use the clustered index, so its important to consider the clustered index when creating other non clustered indexes.
- Avoid overlapping indexes.
- Make sure the indexes are covering the queries being executed.